Computação do Apache Spark no Microsoft Fabric: O que você precisa saber
As experiências de engenharia e ciência de dados no Microsoft Fabric operam sobre uma plataforma totalmente gerenciada do Apache Spark, projetada para entregar velocidade, flexibilidade e simplicidade.
FABRICCOMPUTAÇÃOAPACHE SPARK
Henrique Bueno
4/19/20252 min read


Pools Iniciais: rapidez e praticidade
Os pools iniciais são ideais para quem precisa começar rápido. Eles oferecem sessões do Apache Spark em cerca de 5 a 10 segundos, sem necessidade de configuração manual. Esses pools mantêm clusters do Spark sempre prontos para uso, com nós de tamanho médio que escalam verticalmente conforme a carga de trabalho. Você só é cobrado enquanto a sessão estiver ativa. Tempo ocioso e inicialização não entram na conta.
Pools do Spark: personalização e controle
Para demandas específicas, os pools do Spark permitem total personalização: você define o nome, o número de nós, seus tamanhos e regras de escalabilidade. A criação é gratuita — você só paga pela execução ativa de jobs. Após 20 minutos de inatividade (valor padrão ajustável), o pool é desalocado automaticamente. O tempo de inicialização é maior (cerca de 3 minutos), pois os nós são alocados sob demanda.
Exemplo: um SKU F64 oferece 64 unidades de capacidade, o que equivale a 384 VCores do Spark (64 x 2 VCores x fator burst 3x). Esses VCores são utilizados para distribuir entre os nós do seu pool personalizado.
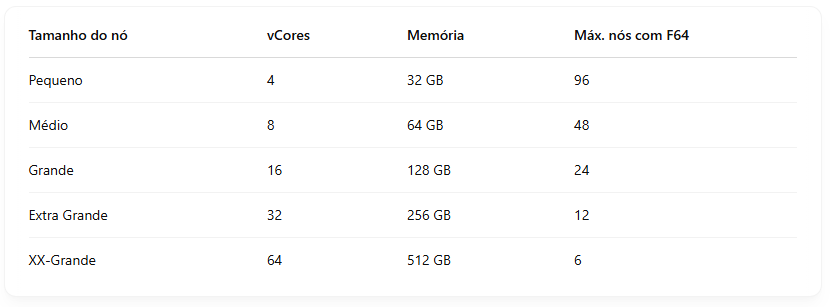
Importante: tamanhos X-Large e XX-Large não estão disponíveis para SKUs de avaliação.
Nós e Arquitetura
Cada instância do Spark tem um nó de cabeçalho e ao menos dois nós de trabalho (mínimo de três no total). O nó de cabeçalho gerencia serviços como Livy, Yarn Resource Manager e o driver do Spark. Os nós de trabalho executam os executors, onde os dados realmente são processados.
Autoscale e Alocação Dinâmica
Você pode configurar o pool para escalar automaticamente os nós com base na atividade. Com o dimensionamento automático habilitado, é possível definir o número mínimo e máximo de nós. Já a alocação dinâmica de executores permite que o Spark ajuste o número de processos conforme a carga de dados, otimizando desempenho sem desperdício de recursos.
Por padrão, o Spark já vem preparado para liberar nós ociosos (spark.yarn.executor.decommission.enabled=true). Se desejar um comportamento mais conservador, é possível desabilitar esse recurso.
Curtiu o conteúdo... Fica ligado aqui no BI com Bueno que sempre estou postando conteúdos de Fabric, Power BI e tudo ligado a dados no universo Microsoft
Dados
© 2024. All rights reserved.