Direct Lake no Microsoft Fabric: A Evolução do Armazenamento para Modelos Semânticos no Power BI
Com o avanço das arquiteturas modernas de dados, surge a necessidade de modelos de armazenamento mais eficientes, rápidos e integrados ao ecossistema do data lake. É exatamente nesse contexto que o Direct Lake se destaca dentro do Microsoft Fabric. Mas o que é esse modo de armazenamento, como ele funciona e quando devemos usá-lo? Neste post, vamos explorar em profundidade o funcionamento do Direct Lake, suas vantagens, limitações e os casos de uso ideais.
FABRICDICASDIREC LAKE
Henrique Bueno
5/3/20252 min read


O que é o Direct Lake?
O Direct Lake é um modo de armazenamento para modelos semânticos no Power BI, desenvolvido especificamente para funcionar dentro do Microsoft Fabric. Ao contrário do modo tradicional de Importação, o Direct Lake carrega colunas diretamente da Tabela Delta (armazenadas em arquivos Parquet no OneLake) para a memória, conforme as consultas são feitas.
Principais Benefícios:
Desempenho em memória com baixo custo de atualização
Integração nativa com Lakehouses e Warehouses no Fabric
Eliminação da etapa de importação tradicional
Alta performance em grandes volumes de dados
Quando usar o Direct Lake?
O Direct Lake é altamente recomendado para:
Projetos orientados por TI com grandes volumes de dados no OneLake
Ambientes onde a latência de dados precisa ser mínima
Situações que exigem atualizações frequentes e rápidas
Reaproveitamento de tabelas Delta já preparadas no lake
💡 Apesar de ser extremamente eficiente, o Direct Lake não substitui os modos de Importação ou DirectQuery. Cada um ainda tem seu espaço dependendo do cenário.
Como funciona o Direct Lake?
O processo do Direct Lake pode ser dividido em quatro pilares principais:
1. Transcodificação (Carregamento de Coluna)
As colunas são carregadas sob demanda — somente quando são utilizadas por uma consulta DAX ou MDX. Isso garante agilidade e economia de memória.
2. Enquadramento
Operação que atualiza a referência para os arquivos Parquet mais recentes no OneLake. Esse processo não recarrega todos os dados, mas analisa metadados para carregar apenas as alterações.
3. Atualizações Automáticas
Habilitadas por padrão, as atualizações automáticas garantem que o modelo esteja sempre alinhado às alterações feitas nas tabelas Delta.
4. Fallback para DirectQuery
Quando o modelo excede os limites de capacidade ou precisa lidar com RLS/segurança em exibições, ele pode recuar automaticamente para DirectQuery — o que impacta negativamente a performance.
Limitações e Cuidados
Embora poderoso, o Direct Lake tem suas limitações:
Sem suporte para colunas calculadas ou modelagem composta
Dependência do tipo de dados suportado pelo Delta Lake
RLS em exibições força fallback para DirectQuery
Sem suporte para regiões cruzadas entre Lakehouse e modelo
Além disso, a escolha do SKU de capacidade do Fabric impacta diretamente no volume de dados suportado, memória disponível e limite de linhas/tamanho de modelo.
🎯 Dica de arquitetura: sempre valide sua estrutura com uma prova de conceito (POC) antes de mover todo seu modelo para o Direct Lake.
Comparação com outros modos de armazenamento
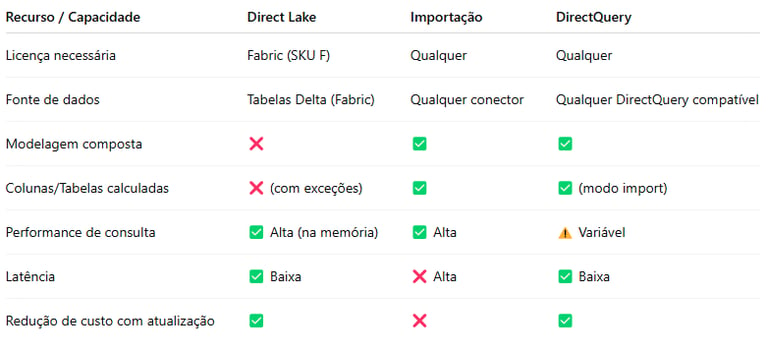
Conclusão: Vale a pena usar o Direct Lake?
Sim — desde que o cenário esteja alinhado ao que o Direct Lake oferece. Para workloads corporativos, com grande volume de dados já no OneLake, e com preparação feita upstream, o Direct Lake proporciona performance, simplicidade e governança.
Por outro lado, para projetos self-service, ou que exigem cálculos dinâmicos dentro do modelo, os modos de Importação ou DirectQuery ainda são as melhores opções.
📌 Resumo prático: se você está no ecossistema Microsoft Fabric, já utiliza Delta Lake e precisa de performance em escala com governança — o Direct Lake é para você.
E se você gostou desse conteúdo, fique ligado aqui no Blog BI com Bueno, que publico sempre novidades, curiosidades e estudos práticos sobre Microsoft Fabric, Power BI e Azure
Dados
© 2024. All rights reserved.